
OpenAI vient de lâcher sa nouvelle bombe : GPT-5. Déployé ce mercredi 7 août 2025, ce modèle n’arrive pas seul. Sous le capot, un système inédit de routage automatique choisit, en temps réel, la “personnalité” d’IA la plus adaptée à votre requête. Sur le papier, c’est la promesse de réponses plus pertinentes, plus rapides… et sans effort côté utilisateur. Mais derrière cette simplification se cachent aussi moins de contrôle, plus de variabilité et, parfois, une addition salée. Voici ce qui change vraiment.
Ce qui change : un seul modèle GPT-5, plusieurs “personnalités” internes
Jusqu’à récemment, chaque usage nécessitait un arbitrage, à savoir GPT-4 « reasoning » pour le raisonnement approfondi, GPT-4 Turbo pour des réponses rapides, etc. Désormais, GPT-5 fonctionne comme une interface unifiée, reposant en coulisses sur plusieurs profils de performance internes (allant de versions légères à des variantes optimisées pour le raisonnement complexe). Si les noms exacts de ces sous-modèles ne sont pas publiquement confirmés par OpenAI, voici ce que chacun propose :
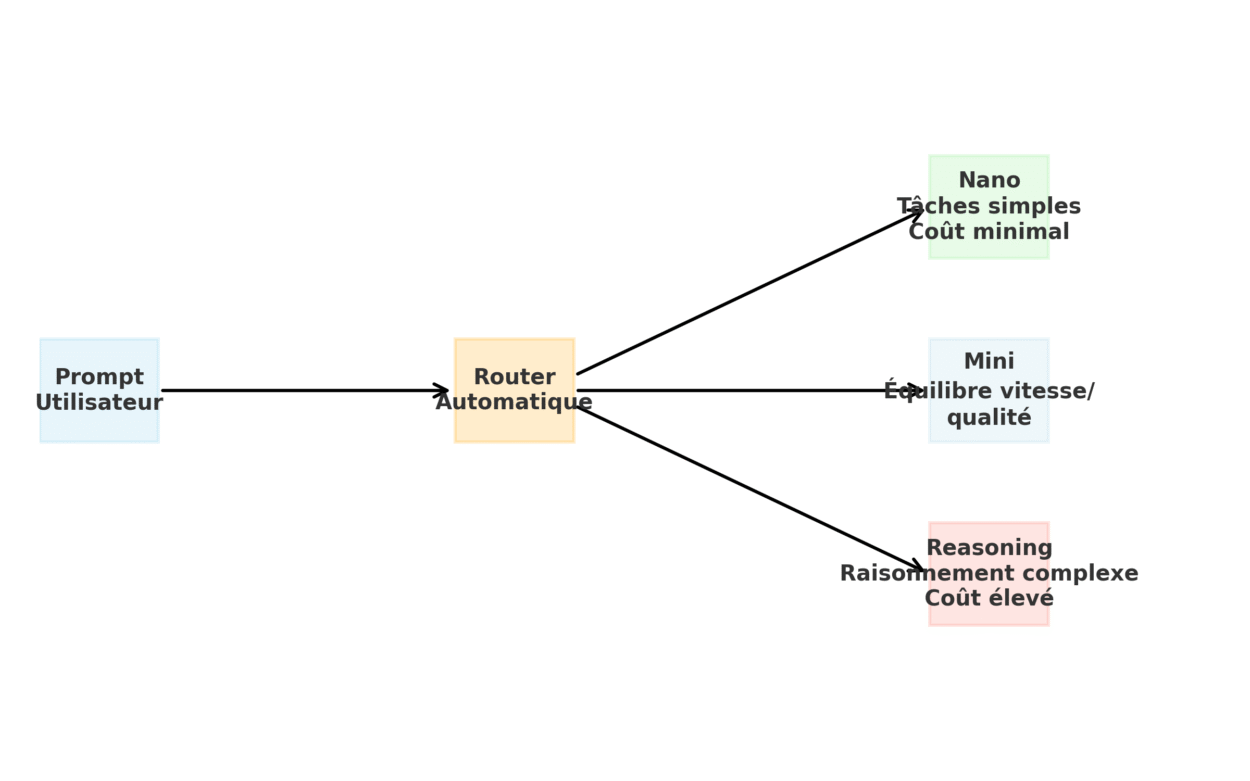
- GPT-5 nano : ultra-léger, rapide, faible coût,
- GPT-5 mini : équilibré, pour les traitements simples,
- GPT-5 reasoning : version la plus puissante conçue pour produire des réponses complètes mais avec un temps de traitement long et couteux.
Le choix du sous-modèle est automatisé et ne s’accompagne actuellement d’aucune indication visible pour l’utilisateur, ce qui limite la transparence sur le processus de sélection. OpenAI n’a pas encore communiqué de méthode permettant d’identifier quel profil a été utilisé pour une requête donnée.
Comment fonctionne l’auto-routage GPT-5 ?
Le système de routage, aussi appelé « router », analyse chaque prompt envoyé à l’IA et s’appuie sur un classifieur propriétaire d’OpenAI. Cet algorithme d’IA chargé de catégoriser les données est entraîné sur un vaste corpus de prompts, bien que les détails techniques exacts n’aient pas été rendus publics.
Il procède en trois étapes :
- Analyse du prompt : longueur, vocabulaire, structure syntaxique
- Estimation de la tâche : rédaction, calcul, code, requête SQL, résumé, etc.
- Routage automatique vers la sous-version la plus pertinente
Le fonctionnement de l’auto-routage peut se résumer en une chaîne simple : Prompt → Router → Modèle.
Dès qu’une requête est envoyée, un classifieur analyse sa structure, sa longueur et son objectif, puis l’oriente automatiquement vers l’une des variantes internes de GPT-5.
L’un des principaux avantages de l’auto-routage réside dans sa simplicité d’usage. L’utilisateur final n’a plus à se soucier du choix du modèle, tout est géré en coulisses. Mais cette commodité a un revers. Le router peut parfois surdimensionner une requête, en activant une version trop puissante du modèle, ce qui entraîne une latence accrue et un coût inutilement élevé. Un routage vers une version trop légère du modèle peut entraîner des réponses incomplètes ou imprécises, en particulier sur des tâches complexes comme le raisonnement logique ou la génération de code, un phénomène potentiellement difficile à identifier sans évaluation approfondie.
| Tâche | Modèle routé | Latence P95 | Coût moyen | Qualité perçue |
| Écriture créative | Standard / Reasoning | 2,8 s | 1 x | 8/10 |
| Refactorisation de code | Reasoning | 4,5 s | 2,5 x | 9,5/10 |
| Data-cleaning | Nano / Mini | 0,7 s | 0,5 x | 7,5/10 |
Tâches d’écriture : un routage automatisé entre fluidité et puissance
Pour les tâches de rédaction créative, le router a tendance à privilégier une variante équilibrée du modèle, optimisée pour le style et la fluidité, tout en conservant une latence modérée. Toutefois, si le texte demandé est particulièrement long ou nuancé, le système peut basculer automatiquement vers la version reasoning, plus puissante, ce qui entraînera une réponse plus lente.
Refactorisation de code : pourquoi le router privilégie le modèle reasoning ?
Dès qu’il s’agit de restructurer du code ou d’en améliorer la qualité, le routeur privilégie quasi systématiquement la version reasoning. Cette dernière offre des réponses plus robustes et cohérentes, bien adaptées aux exigences des développeurs. Le coût peut s’avérer significativement plus élevé avec la version reasoning, notamment pour des tâches complexes comme la refactorisation de code1, bien que les écarts exacts restent non documentés publiquement.
Nettoyage de données, des modèles légers pour des tâches simples et rapides
Les tâches de type data-cleaning (nettoyage de fichiers, suppression d’erreurs, normalisation) sont généralement routées vers les variantes les plus légères. Elles offrent généralement une latence très faible, souvent inférieure à une seconde dans les cas simples. En revanche, ces versions peuvent parfois manquer de rigueur dans les cas limites, comme les arrondis imprécis ou des valeurs aberrantes non détectées.
Moins d’opérations manuelles et plus de pilotage avec GPT-5
Pour les équipes produits et les développeurs, la disparition du choix manuel des modèles représente un gain de temps considérable, plus besoin d’ajuster l’outil au cas par cas. Cette simplification s’accompagne toutefois de nouveaux défis. Cela limite les possibilités de maîtriser finement les réponses, rend plus difficile l’obtention d’un résultat identique avec un même prompt, et oblige à mettre en place des outils de suivi pour comprendre comment le système choisit ses réponses.
Traçabilité, un point faible dans les environnements régulés
L’un des angles morts du système de routage est sa transparence. OpenAI conserve bien des logs2 internes sur les décisions du router, mais les clients n’y ont pas accès. Cela pose un réel problème dans les secteurs sensibles comme la santé ou la finance, en cas d’audit ou de contrôle, il est aujourd’hui impossible de retracer précisément pourquoi une requête a été routée vers telle ou telle version du modèle.
Il est important de ne pas confondre deux mécanismes bien distincts :
- Le router détermine automatiquement quelle version du modèle exécute le prompt,
- Le RAG (Retrieval-Augmented Generation) enrichit ce prompt en amont avec des données issues d’une base externe.
Limites du système : imprédictibilité, debugging complexe et coûts invisibles
L’automatisation du routage a aussi ses revers. D’abord le manque de prévision, puisqu’un un même prompt peut être routé différemment en fonction de facteurs non visibles comme des ajustements algorithmiques, une modification du contexte ou de la charge serveur. Cela rend difficile la stabilité des performances dans le temps.
Ensuite, le debugging3 devient un casse-tête. Reproduire un comportement problématique suppose que le router sélectionne à nouveau exactement la même version du modèle, ce qui n’est pas garanti. Cela complique le travail des équipes d’assurance qualité4 et de support technique.
Enfin, le risque de coûts silencieux liés à l’auto-routage est bien réel. Si le routeur oriente fréquemment les requêtes vers un modèle plus avancé, comme GPT-4 ou GPT-4-turbo sans contrôle explicite, alors la facture mensuelle peut grimper significativement, parfois de 20 à 40 %, selon le volume de requêtes et l’écart de prix entre les modèles.
Ce glissement, discret mais impactant, s’accentue avec des prompts longs ou complexes. Un système de routage intelligent peut alors être configuré pour basculer automatiquement vers un modèle plus adapté au raisonnement ou aux tâches contextuelles. Cette montée en gamme peut parfois induire une latence supplémentaire, même si cela dépend fortement du modèle utilisé et de son optimisation.
Les indicateurs clés de performances essentiels à suivre
Avec l’activation du router automatique, certains indicateurs deviennent essentiels pour piloter la performance et anticiper les dérives. Le premier est le CSAT (Customer Satisfaction Score), qui permet d’évaluer sur une échelle de 1 à 5, la qualité perçue des réponses par les utilisateurs finaux. Un bon thermomètre de l’alignement entre routage et attentes métier.
Autre indicateur clé, la latence P95, c’est-à-dire le temps de réponse observé dans 95 % des cas. Il est particulièrement critique pour les tâches sensibles ou les environnements en temps réel, où chaque seconde compte. Enfin, le coût par prompt ou par ticket devient un levier de pilotage incontournable, surtout dans les contextes de support client, de génération de masse ou d’automatisation à grande échelle. Un routage non maîtrisé vers une version plus coûteuse du modèle (comme reasoning) peut avoir un impact significatif sur les budgets à moyen terme.
Bien que l’auto-routage présente de nombreux avantages, il n’est pas toujours adapté à tous les contextes. Dans certains cas, il est préférable de recourir à un modèle figé, notamment lorsque la réglementation impose une traçabilité stricte, comme dans les secteurs de la finance et de la santé ou encore lorsque les workflows sont critiques et ne tolèrent aucune variabilité. De même, dans les environnements de test, la reproductibilité des résultats est essentielle, ce qui justifie l’usage d’un modèle stable. Une bonne pratique consiste à conserver un mode « forcer le modèle ». Cette action est disponible via l’API et les paramètres avancés. En revanche elle n’est pas possible depuis l’interface grand public.
Avec l’arrivée de GPT-5 et de son router automatique, l’expérience utilisateur devient plus fluide, plus accessible. Il fonctionne en électron libre et n’est plus entre les mains de l’utilisateur qui passe du rôle de pilote à celui de superviseur. Une évolution qui demande de nouveaux outils, de nouveaux réflexes et une plus grande rigueur dans la gestion des usages à grande échelle. Et vous, avez déjà tester GPT-5 ? Qu’en avez vous retenu ? Partagez vos retours et cas d’usage en commentaire.
- C’est le fait de réécrire un code afin de le rendre plus lisible, plus performant et parfois plus conforme aux bonnes pratiques. ↩︎
- Les logs sont des fichiers qui enregistrent automatiquement ce qui est transmis à l’IA pour garder un historique. ↩︎
- Processus qui consiste à repérer, comprendre et corriger les erreurs dans un programme informatique. Il permet de comprendre pourquoi un logiciel ne fonctionne pas. ↩︎
- Assurance qualité aussi connu aussi connue sous l’acronyme QA signifie l’ensemble des méthodes de test et vérification mises en place pour que l’IA fonctionne. ↩︎
Certains liens de cet article peuvent être affiliés.