
Google vient de franchir une nouvelle étape avec Gemini 3 Pro. Plus performant que la plupart de ses concurrents et intégré à l’ensemble de l’écosystème Google, il s’impose comme un pivot stratégique pour la firme. En parallèle, Nano Banana Pro, son nouveau générateur d’images sorti deux jours après, étend encore l’influence de Gemini 3 dans la création visuelle.
Gemini 3 : Evaluation des performances face à GPT-5.1, Claude Sonnet 4.5 et Grok 4.1
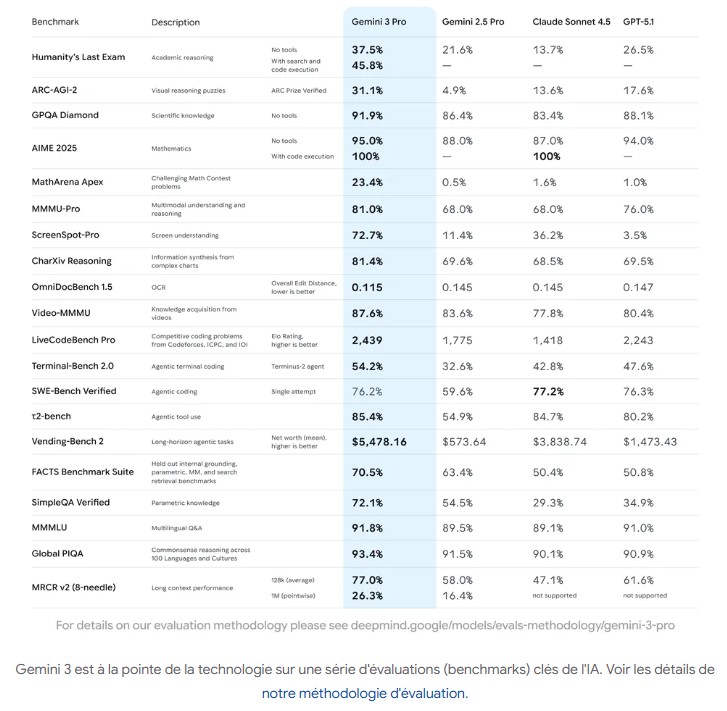
Selon les données internes publiées lors du lancement ce 18 novembre, la version Gemini 3 Pro dépasse les principaux modèles de LLM concurrents, notamment GPT-5.1, Claude Sonnet 4.5 ou Grok 4.1, dans la plupart des tests d’évaluation. Il affiche des scores remarquables sur une large palette de benchmarks : numéro 1 sur LMArena avec 1501 Elo, 37,5 % au « Humanity’s Last Exam » (un « niveau doctorat » sans utiliser d’outils) et 91,9 % au GPQA Diamond. Il atteint même 72,1 % sur SimpleQA Verified pour la factualité, largement au-dessus de ses concurrents. En mathématiques, le modèle établit aussi un score de référence avec 23,4 % sur MathArena Apex.
D’après Google, Gemini 3 serait aussi « le meilleur modèle au monde pour la compréhension multimodale« . Il affiche 81 % sur MMMU-Pro et 87,6 % sur Video-MMMU, signes d’un net progrès dans l’intégration texte-image-vidéo. Côté codage et agents, Gemini 3 arrive également en tête des classements dédiés au développement : 1 487 Elo sur WebDev Arena, 54,2 % sur Terminal-Bench 2.0 (contrôle d’un ordinateur via un terminal) et 76,2 % sur SWE-bench Verified.
Google présente par ailleurs un mode « Deep Think », accessible aux testeurs de sécurité, avant d’être élargi aux abonnés Google AI Ultra. Son raisonnement renforcé améliore encore les résultats de Gemini 3 : 41,0 % au Humanity’s Last Exam, 93,8 % au GPQA Diamond et 45,1 % sur ARC-AGI (avec exécution de code).
Enfin, Gemini 3 a montré des capacités supérieures en planification long terme, en arrivant en tête du Vending-Bench 2. Il utiliserait des outils et prendrait des décisions de manière cohérente sur un an de simulation. Ces chiffres, fournis par Google, traduisent une montée en capacité sur le raisonnement, la cohérence multimodale et la tenue d’objectifs sur des horizons temporels étendus.
Gemini 3 Pro : analyses multimodales, vibe coding et agents IA
Gemini 3 combine multimodalité étendue, fenêtres contextuelles très larges (jusqu’à un million de tokens selon Google) et fonctions agentiques destinées à automatiser des workflows complexes. Le modèle est capable de synthétiser de longs corpus (textes, vidéos, audios…), d’en faire des fiches interactives en générant du code, ou de générer des visuels et infographies. Google nous donne l’exemple d’une visualisation du flux de plasma dans un tokamak, pour représenter les mécanismes de fusion nucléaire. Ou encore d’une analyse de vidéos de matchs de sport avec proposition de plans d’entraînement personnalisés.
Pour les développeurs, Gemini 3 est présenté comme « le meilleur modèle de vibe coding et de codage agentique » que Google ait jamais conçu. Il gère des prompts complexes en « zero-shot », pilote des séquences d’outils et peut exécuter des workflows de bout en bout via la nouvelle plateforme Google Antigravity. Il est même capable de créer des programmes, des jeux vidéo ou encore des sites internet.
Google met aussi l’accent sur la sécurité : Gemini 3 aurait subi la « série d’évaluations de sécurité la plus complète » menée par l’entreprise pour un modèle d’IA, avec des audits externes et des protections contre les « injections de prompt » et les détournements. La disponibilité immédiate de Gemini 3 Pro dans plusieurs produits et l’ouverture progressive du mode Deep Think aux testeurs tend à montrer que Google vise un déploiement large tout en poursuivant des validations de sécurité spécifiques.
Nano Banana Pro : une évolution majeure pour la génération d’images
Deux jours après Gemini 3 Pro, Google a dévoilé Nano Banana Pro (Gemini 3 Pro Image), une mise à jour majeure de son modèle de génération visuelle. Le système peut désormais produire des visuels en 4K, générer une typographie contrôlable (police, texture, calligraphie) et prendre en compte jusqu’à 14 images de référence. Tirant parti des capacités de raisonnement du nouveau modèle, il améliore fortement la fidélité aux images sources et la précision du texte intégré.

Les avancées en constance permettent aussi de conserver la ressemblance de cinq personnes à travers une série d’images, ou encore de générer des structures 3D à partir de plans fournis par l’utilisateur. Les capacités d’intégration d’informations disponibles sur le web (contenus, météo, résultats sportifs, etc.) et de contrôle des angles de vue, héritée du modèle vidéo Veo 3, élargissent encore les cas d’usage, des infographies aux scènes visuelles complexes.
Le modèle est disponible dans l’application Gemini via le mode « Thinking », dans Google Ads, Slides et Vids (Google Workspace), Vertex AI (Google Cloud), et pour les développeurs dans Google AI Studio et Antigravity, ou encore dans l’appli de création vidéo Flow pour les abonnés Google AI Ultra. Il est aussi déjà utilisé dans Adobe Firefly et Photoshop, preuve d’un déploiement très rapide dans les outils professionnels.
A noter que toutes les images fixes sont marquées avec SynthID, un filigrane numérique invisible permettant d’en vérifier la provenance et de déterminer qu’il s’agit d’IA. Le dispositif devrait être prochainement étendu aux vidéos et audios. A part pour les abonnés Google AI Ultra, une watermark visible est aussi affichée sur les images.
Gemini 3 Pro en France : comment y accéder sur le web et l’appli ?
Gemini 3 est intégré à une grande partie de l’écosystème Google. De manière générale, il est accessible :
- gratuitement dans l’application Gemini,
- dans le moteur de recherche Google en « AI mode »,
- pour les développeurs avec l’API Gemini dans AI Studio, Google Antigravity et Gemini CLI,
- pour le milieu professionnel par Vertex AI et Gemini Enterprise.
En France, Gemini 3 Pro est accessible directement via le site gemini.google.com ou l’application mobile, pour tous les utilisateurs, y compris gratuits. Le modèle apparaît parfois sous la mention « Thinking ».
En revanche, l’intégration dans les résultats du moteur de recherche (Google Search), via les AI Overviews (récapitulatif des recherches) et le nouveau « AI Mode » (chatbot), n’est pas disponible en raison de contraintes réglementaires. Pour tester le Mode IA de Google, il faut passer par un VPN et se connecter via google.com/ai depuis un pays autorisé.
Avec Gemini 3 et Nano Banana Pro, Google avance simultanément sur la performance, l’intégration et la diffusion à grande échelle. Le modèle devient la colonne vertébrale de nombreux services, tandis que la génération d’images gagne en stabilité et en précision. Reste désormais à observer comment ces technologies se déploieront en France dans le moteur de recherche et comment les régulations comme la concurrence façonneront la suite.
Certains liens de cet article peuvent être affiliés.
Gil, cet article offre une vision approfondie des progrès de Gemini 3. Les performances et l’intégration du multimédia sont vraiment impressionnantes ! Hâte de voir leur impact en France.
L’innovation de Google avec Gemini 3 et Nano Banana Pro est fascinante ! Imaginer des outils si puissants pour la création visuelle et intellectuelle, c’est comme retrouver un trésor ancien dans l’histoire.
Wow, Gemini 3 et Nano Banana Pro ouvrent de nouvelles voies créatives ! J’ai hâte de tester ces innovations. La fusion AI et design pourrait vraiment révolutionner notre façon de travailler. Inspirant !