
La sortie tant attendue de GPT-5 est arrivée le 7 août dernier. L’occasion pour les utilisateurs de découvrir les promesses, mais aussi les premiers défauts de cette nouvelle version.
Open AI a lancé GPT-5, désormais disponible pour tous les utilisateurs de ChatGPT, gratuits comme abonnés Plus. Cette version promettait une avancée majeure, avec une fenêtre contextuelle portée à 256 000 tokens (≈ 500 pages de texte) dans ChatGPT, et jusqu’à 400 000 tokens via l’API, un real-time router pour diriger automatiquement chaque requête vers la variante interne optimale (Fast, Thinking, Nano…) et un mode Deep Research pour mener des recherches et raisonnements multi-étapes avec plus de structure.
Enfin, Open AI renforce sa modération avec le dispositif Safe Complections qui agit avant, pendant et après la génération, pour détecter et reformuler les requêtes liées à des sujets sensibles tels que la violence, la désinformation ou les incitations illégales. Mais tout cela ne masque pas les défauts présents dans cette nouvelle version.
GPT-5 : des progrès tangibles, mais des réponses qui déçoivent
Malgré ses nombreuses promesses, en matière de mathématiques, de programmation ou de santé et l’introduction d’une architecture unifiée dotée d’un real-time router capable de rediriger automatiquement les requêtes vers la variante la plus adaptée, GPT-5 n’échappe pas aux critiques. Son lancement a été marqué par des bugs et une expérience utilisateur jugée fragmentée, nourrissant la perception d’une régression créative et stylistique, en particulier chez les utilisateurs fidèles à GPT-4o. Les griefs les plus fréquents portent sur un ton jugé froid ou impersonnel, des réponses moins développées qu’attendu et des restrictions d’accès qui limitent la flexibilité d’usage.
« Raisonnement mathématique : Fait encore des erreurs simples. Légères améliorations par rapport à GPT-4. Nécessite des instructions spécifiques pour résoudre correctement les problèmes difficiles.
Logique symbolique (puzzles ARC) : Score faible. Moins bon que des modèles comme Grok 4 sur les énigmes de raisonnement général.
Raisonnement de bon sens : Éprouve des difficultés avec la logique de base, sauf s’il est incité à « penser étape par étape ». Pas de progrès majeur par rapport à GPT-4.
Précision factuelle : Continue à produire des hallucinations. Invente des noms, compte mal les lettres, invente des détails à moins d’être guidé avec précision.
Génération de code : Meilleurs scores aux tests de référence, mais échoue sur des projets complexes. Difficultés avec la gestion d’état, l’intégration et la coordination.
Bilan général : Les progrès sont réels mais limités. Sur certains tests, il est en retrait par rapport aux concurrents. Reste fragile sans indications précises. » – medium.com
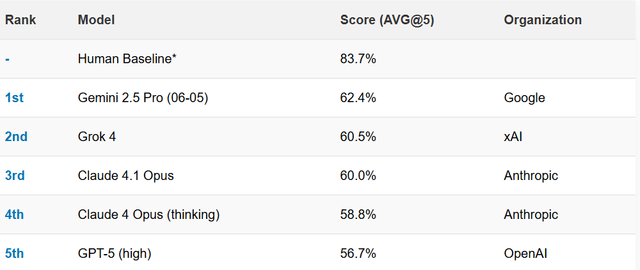
De très nombreux utilisateurs ont d’ailleurs exprimé leur frustration sur Reddit avec un fil nommé « GPT‑5 c’est horrible ». Preuve de la déception générée par GPT-5, selon le classement SimpleBench publié le 8 août 2025, quelques heures seulement après la sortie du dernier modèle. GPT‑5 pointe à la cinquième place, derrière Gemini 2.5 Pro et Grok 4 et loin du niveau humain estimé.
Des failles lors du lancement du real-time router
Autre point au critiqué, le real‑time router, censé diriger chaque requête vers la version la plus appropriée parmi les différents sous-modèles internes, selon la nature de la tâche demandée. L’outil a connu des dysfonctionnements lors de son lancement, ce qu’a admis Sam Altman dans la foulée. Sur le forum Reddit où il répond directement aux utilisateurs, le PDG d’Open AI explique :
« GPT-5 paraîtra plus intelligent à partir d’aujourd’hui, Hier (jour du lancement), nous avons eu un incident grave et le commutateur est resté hors service pendant une partie de la journée, ce qui a rendu GPT-5 bien plus stupide ».
Certains regrettent la disparition (temporaire) des modèles précédents comme GPT-4o (et certaines variantes de test internes), ce qui a frustré une partie des utilisateurs. Sam Altman a depuis indiqué sur son compte X qu’un retour à GPT‑4o pour les utilisateurs Plus était à l’étude. Une stratégie qui pourrait permettre à Open AI de ne pas perdre trop d’utilisateurs au moment ou d’autres intelligences artificielles continuent de se développer.
Elon Musk encense Grok 4 Heavy et le compare à GPT-5
Lancé par xAI, Grok 4 Heavy qu’Elon Musk décrit comme « l’IA la pluplus intelligente du monde » se distingue par une architecture multi-agents qui permet à plusieurs sous-modèles de collaborer pour résoudre des tâches complexes. Sur le benchmark Humanity’s Last Exam, qui évalue les connaissances académiques et les capacités de raisonnement, il atteint 44,4 % avec utilisation d’outils, contre 26,9 % pour Gemini 2.5 Pro et 24,9 % pour o3, comme le rappelle la revue Scientific American. Sur le concours mathématique AIME25, il décroche un score parfait de 100 % comme le rapporte plusieurs médias spécialisés comme Beebom. Selon des tests indépendants, GPT-5 obtiendrait un résultat de 94,6%. Fidèle à son style provocateur, Elon Musk s’est amusé à comparer sur X, Grok 4 Heavy et GPT-5, en affirmant que Grok 4 Heavy était meilleur que GPT-5.
L’intelligence artificielle d’Elon Musk se singularise par rapport à ses concurrents sur un raisonnement avancé et une originalité de ton qui tranche avec les modèles plus formels. En revanche, ses limites incluent une vitesse d’exécution plus lente, un coût élevé (environ 300 $/mois) et plusieurs controverses liées à des propos non modérés, relevées par TechCrunch et TechRadar.
GPT-5 vs Grok 4 Heavy : qui est le meilleur ?
On a voulu comparer les différences entre les deux intelligences artificielles et si l’affirmation provocatrice d’Elon Musk correspondait aux données disponibles. Voici donc un tableau comparatif entre les deux concurrents.
| Critère | GPT-5 | Grok 4 Heavy |
| Architecture | Unifiée avec routage intelligent, 256 K tokens, personnalités | Multi-agents collaboratifs, outils intégrés |
| Benchmarks | SWE-Bench : 74,9 % ; AIME : 94,6 % ; HealthBench : 46,2 % | Humanity’s Last Exam : 44,4 % ; AIME25 : 100 % |
| Style / créativité | Stable, ton parfois jugé froid | Ton provocateur, créativité forte, controverses modération |
| Accessibilité | gratuit pour l’usage de base, avec une API facturée selon le volume de tokens (tarification officielle disponible sur le site d’OpenAI. | 300 $/mois, usage niche haut de gamme |
Sur la base des benchmarks publiés et des retours utilisateurs, GPT-5 se démarque par sa polyvalence et sa sécurité renforcée, tandis que Grok 4 Heavy surpasse GPT-5 sur certains tests de raisonnement pur comme Humanity’s Last Exam ou AIME25.
En l’absence d’AGI (Intelligence Artificielle Générale), aucun modèle n’est alors universellement meilleur que l’autre. Dans ce cas, la meilleure est celle correspondant le plus à vos priorités (sécurité créativité, prix), votre environnement (professionnel, éducatif ou environnemental) et votre style de travail (préférence de ton, niveau de détail attendu). Et vous que pensez-vous de GPT-5 ? Préférez-vous Grok 4 Heavy ou une autre IA à celle d’Open AI ? Dites-le-nous dans les commentaires.
Certains liens de cet article peuvent être affiliés.