
Le 16 décembre 2025, OpenAI a dévoilé le nouveau modèle de son générateur d’images intégré à ChatGPT. Nommé GPT Image 1.5, ce dernier cherche à simplifier la création d’images tout en améliorant la qualité, la fidélité aux instructions et les possibilités de retouche. Accessible à tous les utilisateurs de ChatGPT, l’outil est destiné à des usages à la fois personnels et professionnels. Mais que vaut-il face aux concurrents comme Nano Banana Pro et Gemini 3 de Google, et d’autres acteurs de l’IA générative ? Comment en tirer le meilleur parti ? Suivez le guide !
Un nouveau générateur d’images au cœur de ChatGPT
Depuis mars 2025, ChatGPT dispose de son propre moteur de génération visuelle, intégré nativement au chatbot, sans nécessiter d’outil externe ou de modèle séparé. Cette évolution marque une rupture avec les générations précédentes, qui reposaient sur DALL·E. Elle a notamment pour objectif de rendre la création d’images aussi accessible que la rédaction de texte, via une interface déjà largement adoptée par le grand public et les professionnels.
La nouvelle version de GPT Image, dévoilée mi-décembre, est censée améliorer ses possibilités et ses fonctionnalités. Selon OpenAI, GPT Image 1.5 se distingue par une meilleure compréhension des instructions textuelles et une capacité accrue à modifier des images existantes sans altérer les éléments non concernés. Le modèle serait également plus rapide, avec des temps de génération sensiblement réduits par rapport à la version antérieure. Ces améliorations lui ont permis de se hisser en tête de certains benchmarks spécialisés, notamment sur des classements communautaires dédiés à la génération d’images à partir de texte, comme LMArena et ArtificialAnalysis.
Une interface dédiée à la création visuelle dans ChatGPT
Le déploiement de GPT Image 1.5 s’accompagne de l’apparition d’un nouvel espace baptisé « Images » dans l’interface de ChatGPT. Accessible depuis le menu latéral, cette section permet de retrouver l’ensemble des images générées, mais aussi d’accéder rapidement à la zone de saisie des instructions.
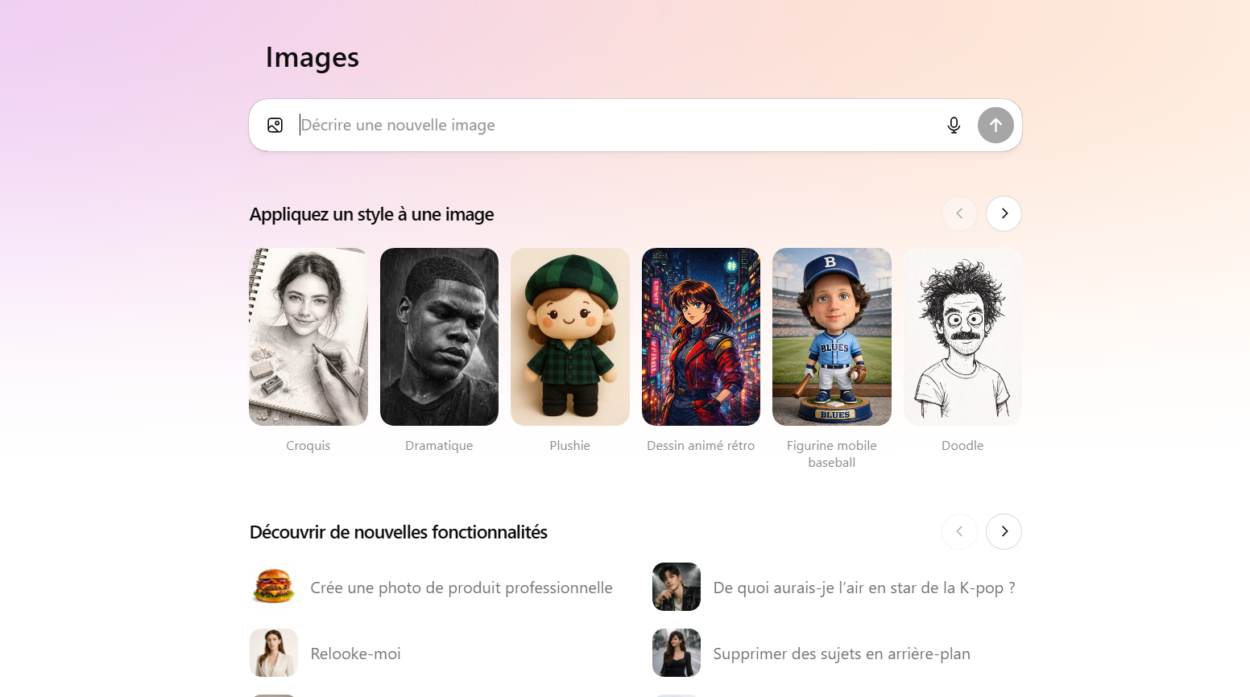
Cette organisation répond à un double enjeu. D’une part, elle facilite la gestion et la réutilisation des visuels créés. D’autre part, elle encourage une approche plus itérative, où l’utilisateur peut revenir sur une image existante pour la modifier, l’améliorer ou l’adapter à un nouveau contexte.
L’interface propose également des suggestions de styles, conçues pour orienter les utilisateurs moins expérimentés. OpenAI cherche ainsi à abaisser la barrière à l’entrée, tout en conservant des possibilités avancées pour les profils plus aguerris.
GPT Image 1.5 : des performances en hausse, mais encore perfectibles
Sur le plan technique, GPT Image 1.5 affiche des progrès notables en matière de qualité visuelle. OpenAI met en avant une meilleure gestion des détails, notamment dans les scènes complexes ou les compositions impliquant plusieurs visages. Le rendu global se veut plus naturel, avec une réduction des artefacts visuels fréquemment observés dans les versions précédentes.
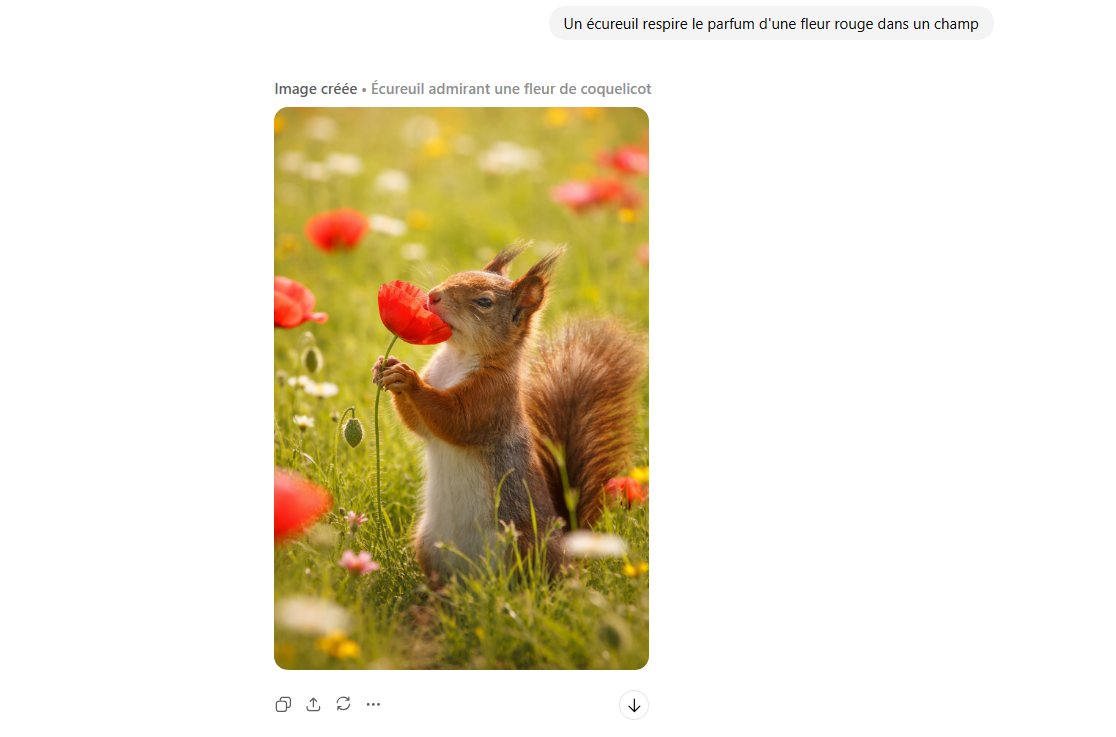
Le suivi des instructions constitue un autre axe d’amélioration majeur. Le modèle est conçu pour générer « des compositions originales plus élaborées » ou appliquer des modifications ciblées à une image importée, en respectant au mieux la demande formulée par l’utilisateur. Cette capacité de retouche localisée limite les reconstructions complètes de l’image, un défaut souvent reproché aux générateurs antérieurs.
Néanmoins, les premiers retours soulignent que certaines incohérences subsistent, en particulier lors de modifications très précises ou impliquant des éléments textuels complexes. Le modèle peut alors produire des résultats approximatifs, rappelant que la technologie reste en phase d’amélioration continue.
Retouche, transformation et inpainting : les fonctionnalités clés
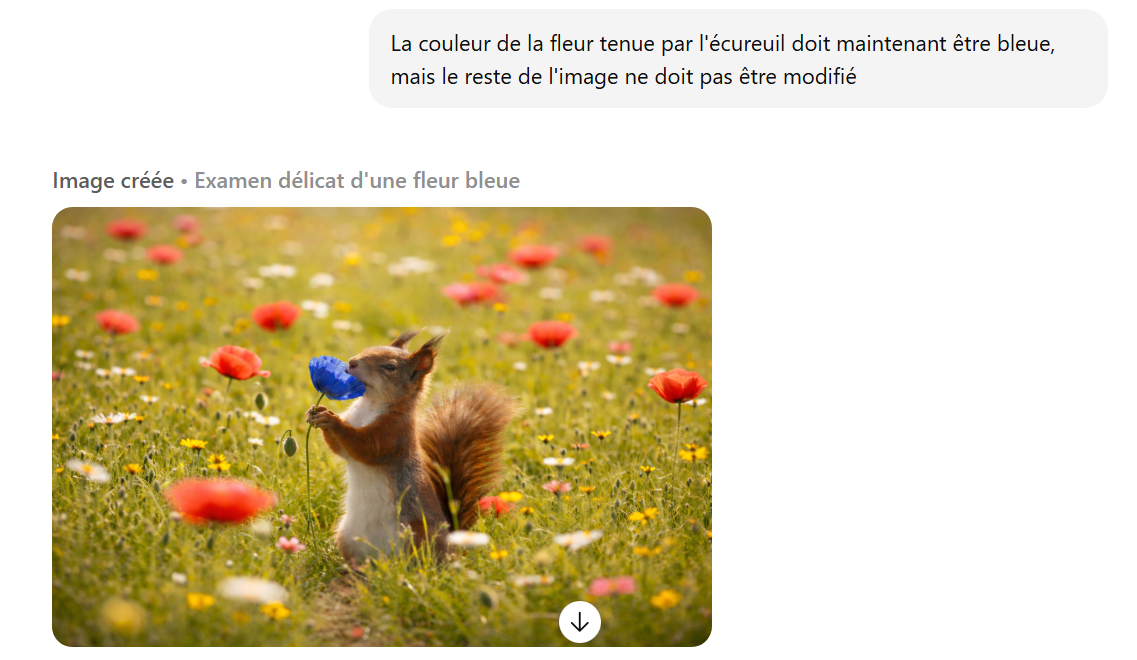
L’un des apports centraux de GPT Image 1.5 réside dans ses capacités de retouche avancées. Le modèle permet d’ajouter, de supprimer ou de modifier des éléments au sein d’une image existante, ou de modifier le format, sans altérer le reste de la composition. Une approche souvent qualifiée d’inpainting, comme dans Midjourney.
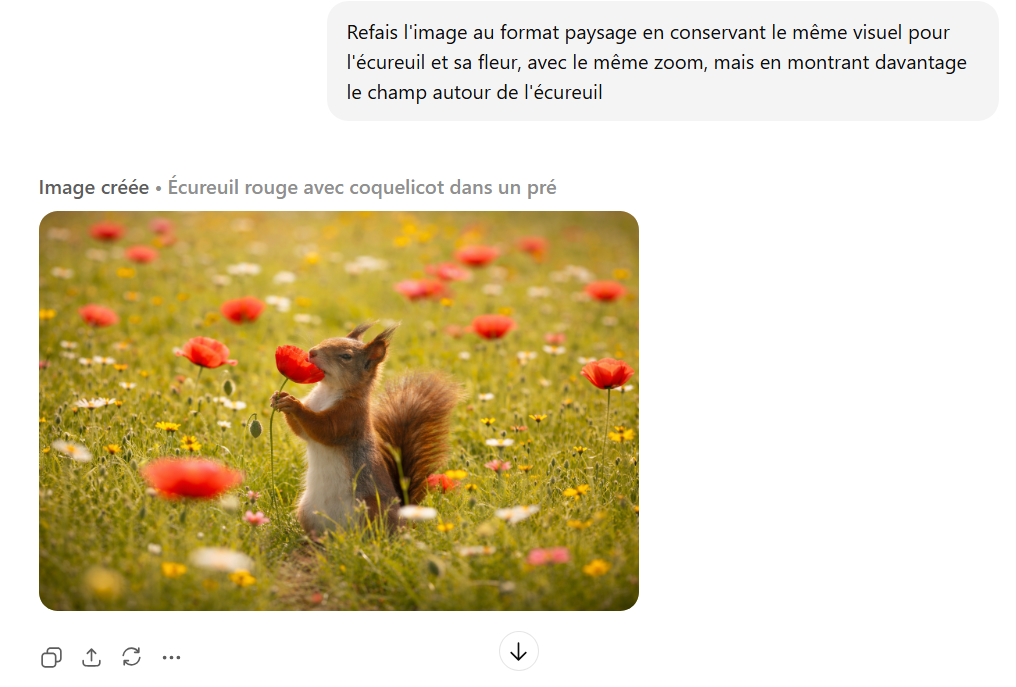
Les transformations globales constituent un autre atout important. L’IA est capable de modifier l’ambiance, le style ou certains aspects visuels tout en conservant la structure et les détails essentiels de l’image d’origine. Cette fonctionnalité se révèle particulièrement utile pour décliner un même visuel selon différents contextes ou supports.
Dans les deux cas, la clé réside dans la clarté des instructions fournies. Plus la demande est précise, plus le modèle est en mesure d’appliquer des changements en adéquation avec vos intentions.
Génération et intégration de texte dans les images
Un autre progrès notable concerne la gestion du texte intégré aux images. GPT Image 1.5 améliore sensiblement le rendu typographique, y compris pour des textes denses ou de petite taille. Le modèle prend désormais en charge des formats structurés, comme le Markdown, et se montre plus à l’aise avec les infographies ou les visuels informatifs.
Pour obtenir un résultat exploitable, il est recommandé de préciser les contraintes liées au texte : lisibilité, style typographique, hiérarchie visuelle et emplacement. Cette capacité à produire des images mêlant visuel et information textuelle élargit considérablement les cas d’usage, notamment pour la communication, l’éducation ou le marketing.
Malgré ces avancées, la génération de texte reste un exercice délicat pour les modèles d’IA, et peut nécessiter plusieurs itérations pour atteindre un rendu parfaitement cohérent. De plus, certains tests affirment que les infographies générées par Nano Banana Pro de Google restent de meilleure qualité et plus créatives.
Images de référence et analyse visuelle
La fonctionnalité de retouche ne s’applique pas nécessairement à une image générée dans ChatGPT. En effet, GPT Image 1.5 permet également de travailler à partir d’images importées.
Ceci a plusieurs avantages. Par exemple, l’image de référence peut servir de base pour générer une nouvelle version modifiée, et plusieurs visuels peuvent être combinés en une nouvelle création. Mais une image de référence peut également être analysée, via une demande envoyée à ChatGPT, afin d’en faire une description détaillée. Cette dernière pourra ensuite être réutilisée, sous forme de prompt, pour générer de nouvelles images similaires.
Cette approche est particulièrement utile lorsque le rendu souhaité est difficile à décrire uniquement par du texte. Elle facilite la reproduction d’un style visuel ou d’une composition spécifique, tout en laissant la possibilité d’introduire des variations contrôlées.
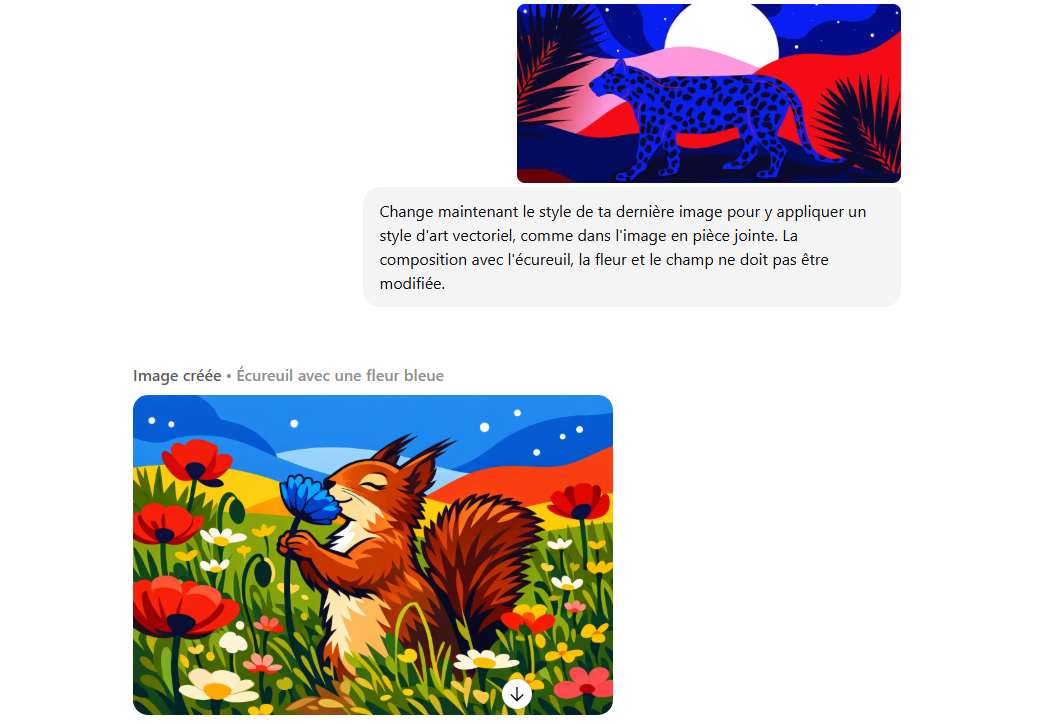
L’utilisation combinée d’images de référence et d’instructions textuelles constitue l’une des approches les plus efficaces pour obtenir des résultats cohérents sur plusieurs générations successives.
Formats, styles et réalisme visuel de GPT Image 1.5
Le nouveau générateur d’images prend en compte les contraintes de format dès la génération. Il est ainsi possible d’adapter un visuel à différents supports, qu’il s’agisse d’un affichage numérique ou d’une impression. Cette prise en charge native limite les besoins de recadrage ou de retouche ultérieure.
Sur le plan stylistique, GPT Image 1.5 se montre capable de produire aussi bien des images illustratives que des rendus photoréalistes. Le niveau de réalisme dépend en grande partie des indications fournies dans les instructions, notamment en ce qui concerne la lumière, la profondeur de champ ou la texture des matériaux.
Ces capacités ouvrent la voie à des usages variés, allant de la création artistique à la production de visuels professionnels, en passant par la conception de maquettes ou de supports de communication.
Le rôle central du prompt engineering
La qualité des images générées dépend largement de la formulation des instructions. Le prompt engineering, souvent décrit comme l’art de dialoguer efficacement avec l’IA, s’impose comme une compétence clé pour exploiter pleinement GPT Image 1.5.
Structurer une demande en précisant l’ambiance, le style visuel, les éléments principaux et les contraintes techniques permet d’obtenir des résultats plus conformes aux attentes. À l’inverse, des consignes vagues conduisent généralement à des images génériques et difficilement exploitables. Même si les suggestions de styles sont là pour vous faciliter la tâche.
Cette logique s’applique également aux modifications d’images existantes. Décrire précisément ce qui doit changer, et ce qui doit rester intact, aide le modèle à effectuer des retouches ciblées sans dégrader l’ensemble du visuel.
Accès, modèles et limitations d’usage
GPT Image 1.5 est disponible pour tous les utilisateurs de ChatGPT et dans d’autres outils basés sur l’IA, sous le nom « gpt-image-1.5 », via l’API d’OpenAI. Le modèle est annoncé comme compatible avec l’ensemble des configurations proposées par la plateforme. Toutefois, certaines limitations subsistent selon le type d’abonnement.
Les utilisateurs de la version gratuite sont limités à quelques générations quotidiennes, tandis que les abonnements payants offrent une plus grande liberté d’usage. Ce qui permet de faire découvrir l’outil, même en mode gratuit, tout en réservant les usages intensifs aux formules avancées.
Depuis l’été 2025, GPT-5 est devenu le modèle par défaut pour la compréhension et les réponses aux prompts dans ChatGPT. C’est lui qui analyse les demandes de génération d’images dans le chatbot, avant de faire appel à GPT Image 1.5 pour la création visuelle. Les modèles antérieurs à GPT-5 restent accessibles aux abonnés payants pour des besoins spécifiques, mais on tendrait progressivement vers l’utilisation d’un moteur unique, capable d’adapter ses performances selon la demande.
Plus rapide, plus précis et mieux intégré à l’interface de ChatGPT, GPT Image 1.5 vise à démocratiser la création visuelle en offrant des fonctionnalités avancées de génération et de retouche d’images. Si certaines limites techniques persistent, notamment sur les modifications très fines ou le rendu textuel complexe, l’outil s’impose déjà comme une solution polyvalente pour produire, adapter et décliner des images à partir d’instructions textuelles. Son efficacité repose toutefois sur un élément clé : la capacité de l’utilisateur à formuler des demandes claires et structurées, condition indispensable pour en tirer pleinement parti. GPT Image 1.5 doit également faire face à une concurrence élevée, notamment avec Nano Banana Pro, qui semble encore produire des infographies plus qualitatives.
Certains liens de cet article peuvent être affiliés.